
ChatGPT和其它文本-图像生成器的爆火,让人领略到了生成式AI模型的力量。除了生成式AI几种不同的应用外,生成技术如GAN和扩散模型还被用来创建合成数据,解决企业的实际痛点。
Gartner指出,到2024年,60%用于开发AI和分析项目的数据将是人工生成的,到2030年,它将完全超越AI模型中的真实数据。
AI需要大量的数据才能很好地运作,虽然企业每天都会产生大量的数据,但由于法规或质量原因(如数据不完整、不准确或不一致等),其中很大一部分无法使用。而合成数据可以使开发者以理想的规模、速度和控制来训练和测试模型,这是使用真实世界数据难以做到的,而且只需花费一小部分成本。
本文将讨论合成数据在企业中的实际应用,并分享我们对市场机会的看法。
当今合成数据的应用案例
合成数据是指由生成式AI、规则、统计模型、模拟、随机生成或其它技术产生的人工数据,用于重新创建或增强原始数据集。合成数据的应用很多,这里我们将重点讨论三个关键需求和现实应用。
1. 隐私保护:目前,企业面临的一个巨大瓶颈是无法处理他们的客户或交易数据,原因是个人身份信息(PII)受到法规的严格保护。通过合成数据,开发人员可以在保持所有统计数据特征的情况下,根据原始数据重新创建一个完全匿名和保护隐私的数据集。
其中一个实际例子,总部位于维也纳的Mostly AI公司最近与Telefonica合作,合成了数百万个CRM记录,并以100%符合GDPR的方式解锁了80-85%的客户数据。这一成果意义重大,因为公司现在可以更好地了解客户行为,运行预测分析,甚至将这些数据变现。这对于金融服务、保险、医疗健康调研、电信等受到严格监管的行业而言尤其重要。
2. 数据增强:如前所述,由于缺乏足够多的高质量数据,且获取数据的成本和时间都太高,合成数据为扩展训练数据集提供了一种更便宜、更快捷的替代方法,也可以提高AI的准确性,例如用在计算机视觉和NPL模型中。
在动态环境中,训练机器人对数以千计的物体进行学习是一个痛苦而漫长的过程。能够基于物体的逼真模拟(如不同颜色、纹理或类型)数据来训练算法,而不必收集大量的真实世界数据,可以节省大量成本。Datagen是一家以色列的合成数据公司,让用户可以完全根据参数(如身份和人口统计信息、环境和照明、相机设置等)配置数据集。
3. 预测边缘情况:合成数据公司能够产出“极端情况”样本,以便ML模型学会识别它们。这在真实世界数据稀缺或难以获得的情况下特别有用,例如在开发自动驾驶汽车或医疗诊断系统时。加州的Parallel Domain平台就是其中一个例子,该平台正在开发数千个不同的场景,以扩展感知模型,为现实世界的不可预测性做准备。
探索合成数据的市场机会
随着一些初创公司开始提供合成数据生成工具、平台及服务,合成数据市场正在快速增长。我们看到了多种多样的商业模式,相信合成数据会随着时间的推移变得商品化,而带给消费者的价值很可能来自于数据生成以外的模式。下面,我们收集了该领域的相关初创公司和开源项目的部分名单,按结构化和非结构化数据进行了分类。
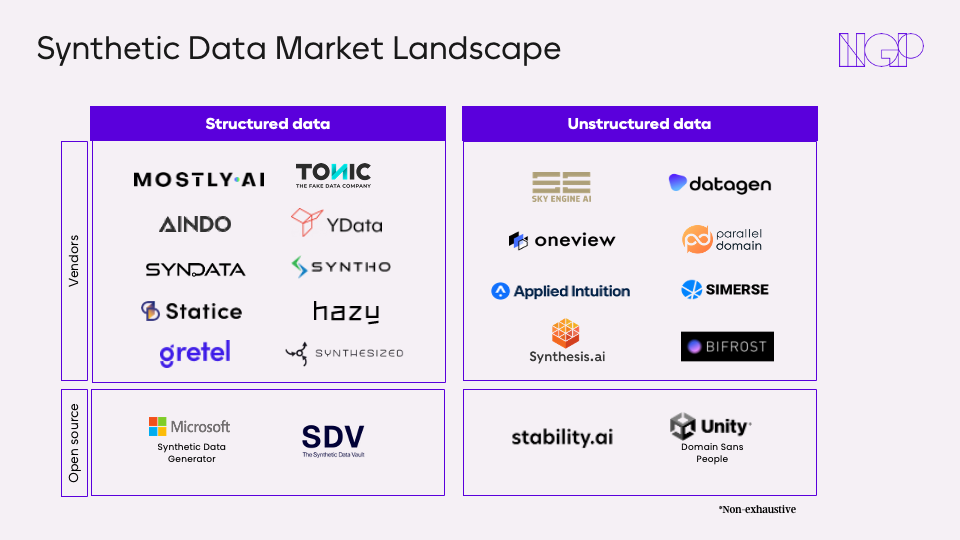
专注于结构化数据(如文本、表格等)的初创公司,我们认为他们的差异化大多数来自于端到端的方法。这意味着,平台允许客户进行数据转换,检查输入数据的质量,生成他们自己的合成数据集,训练模型,并最终能够与企业的数据堆栈中的其他平台整合。例如,总部位于西雅图的Ydata公司正在建立一个以数据为中心的开发平台,帮助数据科学家对数据质量进行可视化和改进,并更快地在单一平台上部署AI。成功的商业模式会有很多,但总的来说,依靠第三方集成的初创企业需要确保软件与其他产品的无缝集成,同时提供良好的客户体验。
专注于非结构化数据(如视频、图像等)的初创公司,我们的观点是,其竞争优势来自于降低合成数据生成过程的技术门槛,例如,可以让任何数据科学家或开发人员在没有3D设计经验的情况下建立3D模型和模拟。西门子的内部Synth AI软件正在使用类似的方法,帮助制造商自动进行机器视觉训练,不需要专家,只需上传CAD数据,然后将其转化为随机合成图像,用于自动训练ML模型。另一个例子是总部设在伦敦的Sky Engine,它正在开发一个专有的基于物理学的渲染引擎,可以使用python API进行控制,并提供卓越的图像和视频质量。在我们看来,这可以大大降低实现价值的成本和时间。
合成数据将改变AI的开发方式
合成数据并非是一个新的想法,但目前在实际应用中越来越受到关注。获得合适的数据对AI的开发至关重要,但它可能是困难的、昂贵的和耗时的。合成数据即将从根本上改变AI的开发方式,这种转变有望通过推动创新和释放各行业的新机会,对经济产生重大影响。
我们诺基亚成长基金对快速发展的AI领域的未来感到振奋,非常欢迎具有挑战性的意见和评论。
相关文章

insights | DeepTech Unleashed 第二集:与政府合作的秘诀——对话 Shark Robotics 创始人兼 CEO Cyrille Kabbara


Insights | DeepTech Unleashed 第一集:与 ANYbotics 首席执行官 Péter Fankhauser 探讨企业销售

Insights | NGP Capital “Future Unleashed (Un)”论坛的 3 个重要观点

