
LLM采用呈指数级增长
当今的现实是,你不必是Gartner分析师也能看得出,我们正处于生成式AI爆火周期的顶端。当OpenAI在2022年11月发布ChatGPT后,普通消费者得以第一手了解到自谷歌大脑Transformer论文发布以来我们所取得的巨大进展,更重要的是LLM(大语言模型)如何对日常工作和生活带来变革。
与Instagram或TikTok等本世纪最具传播性的应用程序指数级增长相比,ChatGPT用户增长曲线看起来更像SpaceX的发射:5天内达到100万用户,不到两个月达到1亿用户。就像互联网使信息变得唾手可及一样,LLM的采用正在使合成民主化。从五年级学生到网络安全人士,大家都在利用这项技术提高他们目前自身的能力。
随着用户规模的扩大,随之而来的是一大批开发人员开始寻找高价值用例,这些案例可以通过自动化或重新构思来实现,他们无需花费数亿美元进行模型开发和训练,只需利用基础模型提供者(如OpenAI、Anthropic、HuggingFace等)发布的API库即可。
根据Databricks “2023年数据+AI状况报告”,从2022年11月到2023年5月初,使用SaaS LLM API的公司数量增长了1310%。难怪风险投资公司等开始振臂高呼:"下一个iPhone时刻已经来临",这很可能是千真万确的。
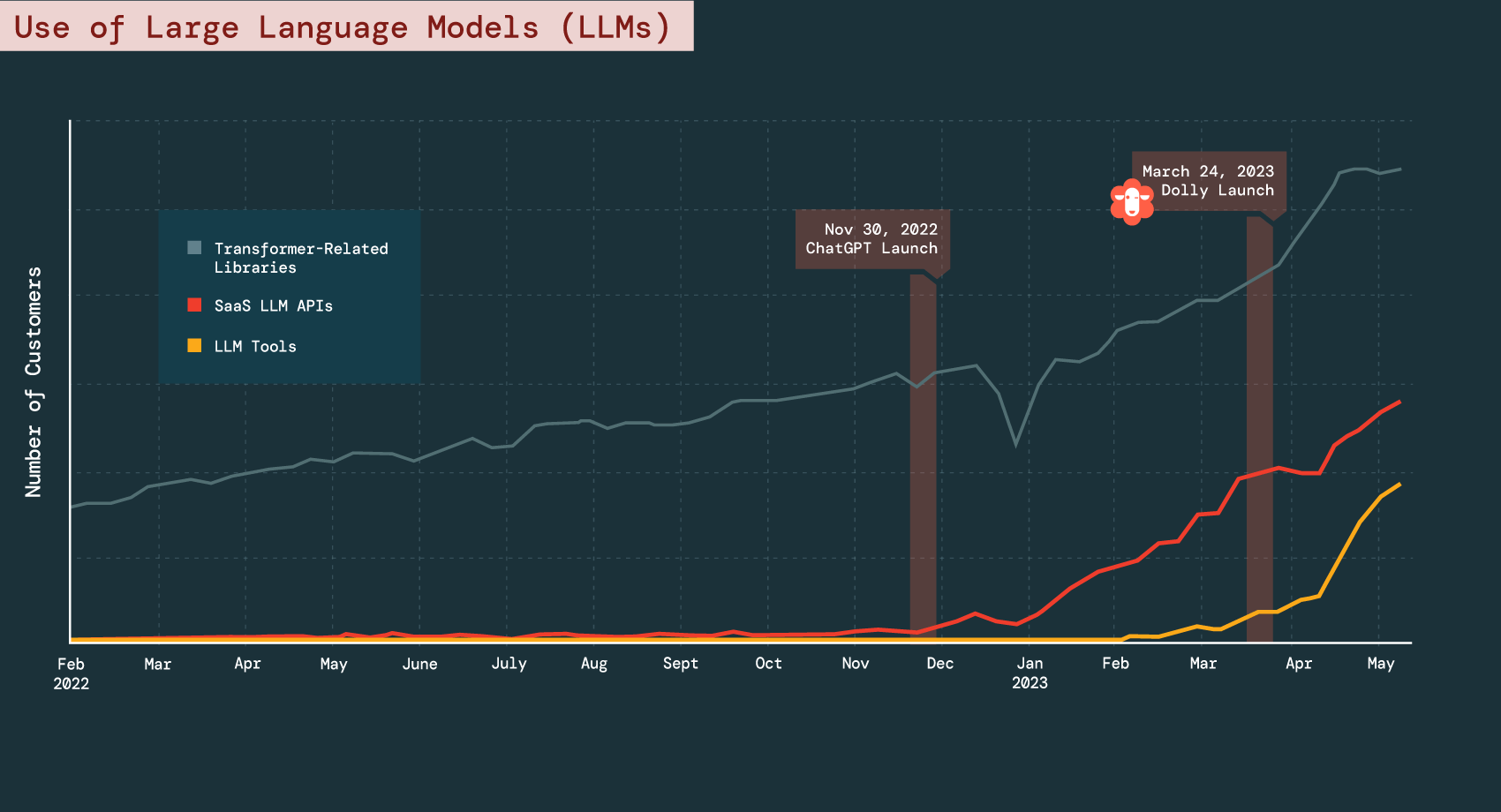
来源:Databricks
随着大语言模型规模的扩大(包括参数数量和训练标记数),它们的能力持续得到提升,为现有的和新的颠覆者提供了更大的动力,利用这些模型建立或增强整个业务。
尽管一些闭源的巨头公司发布了微调API,但在被广泛采用中仍面临着相当大的阻力,如数据安全和隐私挑战、训练成本、以及由于这些模型不在内部基础设施上托管而产生的运行时间问题等。然而,3月初,Meta的LLaMA在4chan上的意外泄露,导致了开源领域的创新和实验的大量涌现。开发者社区表明,在部署LLM时,并不总是越大越好,而且新的微调技术可以在不影响性能的情况下,大幅度降低训练成本。
其中的例子包括Vicuna和Koala这两个模型,它们在性能阈值方面与大型科技公司的竞争对手相当,但仅需很小一部分的训练成本,分别为300美元和100美元。
这对应用层为什么很重要?这些进展证明,开源模型可以在特定的用例任务中同样表现出色,而训练成本可以被大型企业和新的初创公司接受。这一发展表明,模型层将变得商品化(谷歌-我们没有护城河,OpenAI也没有),并将重点转移到应用层。
那么,初创企业如何在生成式AI的应用层建立可防御性?让我们来探讨一下创始人可以采取的五个策略,这些策略可以巩固他们在应用层的地位,并开辟一个独特的竞争优势。
1) 了解LLM的能力及局限性
了解LLMs的能力及局限性是第一步。虽然这些模型可以生成类人文本,是内容创建和文本总结等常见任务的强大工具,但它们也有其局限性,例如缺乏行业或特定用例的背景,有可能产生错误,训练和使用成本过高,以及对输入措辞的敏感。
2)采用可组合性来提高表现
鉴于这些特点,发展长期价值和差异化的一个策略是建立可组合性,将专有模型与LLM串联起来,以解决更加专业及行业特定的用例。这可能涉及到在大型的工作流程中为特定子任务进行内部和闭源模型的微调。例如,我们的投资组合公司Observe AI在为客服中心人员提供辅导中,一直与内部模型并行使用BERT。他们的成功是基于其在过去5年中所获取的大量相关文本数据。
3)注重数据质量,而非数量
另一个策略是注重数据的质量,而不是数量。随着LLM变得更加商品化,其价值将转向用于训练和微调这些模型的数据。那些能够收集别人难以复制的、专有的、高质量数据的公司将拥有强大的竞争优势。这可能需要对数据收集和标注工作的投资,发展伙伴关系以获取专有数据,或创建长期反馈机制以不断改进数据。我认为,Nuance Communications在2021年4月能被微软以197亿美元收购,就是因为该公司拥有的数据优势。
4)打造工具,增强可用性和有效性
除了数据之外,另一个关键的差异化领域是开发工作流程和工具,以增强LLM的可用性和有效性。这可能需要创建用户友好的界面,开发工具来监测和控制模型的输出,或将模型整合到现有的软件和系统中。然后,LLM成为一个更为复杂的工作流程中价值链的一个环节,其输出是一个自动化的行为。
可防御性将在整合的数量和易用性中产生。举个例子,虽然ChatGPT本身非常强大,但通过开发插件,它的功能得到了指数级的扩展,使得平台能够与现有应用程序协同工作,提供端到端的功能。最终,能够让LLM更加易于终端用户使用的公司将获得极大优势。
5)优先践行AI责任
最后,鉴于LLM产生的道德和社会影响,公司须优先考虑高度践行AI责任,这样可以使自己与众不同。这可能涉及到实施强有力的措施以确保数据隐私和安全,开发机制以检测和减少模型的偏见,并对模型的能力和局限性保持透明。那些承诺对AI保持高度道德标准的公司,不仅会与用户建立信任,也会为该领域的监管发展做好更充分的准备。可以说,苹果公司的主导地位正是以这一事实为前提的。
尽管基础模型在自然语言理解和生成方面产生了重大突破,但专注于可组合性、数据质量和端到端自动化的新兴颠覆者将在应用层面上创造长期价值。
从诺基亚成长基金的角度,我们对那些在基础模型之上构建方案以解决大型企业痛点的早期阶段公司非常感兴趣。如果你正在构建的与我们的数实大融合主题相符,或者有任何与本文相关的问题或反馈,欢迎通过LinkedIn或电子邮件联系我 eric@ngpcap.com。
图源:Unsplash
相关文章

Insights | 了解LLM Agent


Insights | 下一代地球观测及其与人工智能的深度融合

Insights | AI遇见工厂:我们为什么投资Daedalus

